AI & Scientific Discovery - Trends in AI: Nov. '25
- Dinos Papakostas

- Nov 24, 2025
- 9 min read
This month’s Trends in AI webinar focused on something that’s rapidly moving from hype to reality: AI for scientific discovery, especially in chemistry, pharmaceuticals, and materials science.
Here is a distilled recap: from European regulation and compute, to Gemini 3 and new open models, and AI “co‑scientists” that run multi‑hour experiments.

*** Join our Luma community to stay up to date with our upcoming events! ***
Europe Hits Pause (But Not Stop) on the AI Act
The biggest policy news: the EU AI Act is delayed. Rumors were confirmed that enforcement timelines are being pushed back, largely due to pressure from US Big Tech that claimed they couldn’t meet the August 2026 deadline for high‑risk use cases. The related "Omnibus Act" is also being reworked to simplify the regulatory tangle. Crucially though, the content of the AI Act hasn't been gutted, as the delay is about readiness, not rollback.
Real European Compute, Finally
For years Europe has talked about "AI sovereignty" without enough hardware to back it.
That’s starting to change:
Schwarz Group (parent of Lidl) is building what will be Europe's largest AI data center near Berlin: 100K GPUs, roughly 10× larger than the planned Deutsche Telekom - NVIDIA collab.
The RAISE initiative from the European Commission aims to support AI talent and R&D with:
GPU access (via EuroHPC)
Shared data infrastructure
Research funding (though ~€100M across the EU won't exactly flood labs with resources)
SAP's Course Correction on “Sovereign AI”
After catching flak for branding an OpenAI + Azure stack as "sovereign European AI", SAP has leaned back toward local champions. At a Franco-German digital sovereignty summit, SAP announced a deeper partnership with Mistral, integrating Mistral models in their enterprise stack. The story of European "sovereign AI" is now more credibly Mistral-shaped than OpenAI-shaped.
Frontier Models: Gemini 3, GPT-5.1, and TPU Muscle
Gemini 3: Google Back on Top (for now)
Google finally ended a quiet spell with Gemini 3, and the numbers are strong:
State-of-the-art on most major benchmarks, including multimodal understanding, document parsing, agentic tool use, and parametric knowledge.
The only meaningful loss: software engineering, where Claude 4.5 keeps a narrow lead.
On the widely watched LMSYS Arena, Gemini 3 is the first model to (almost) break the 1500 Elo mark, pulling ahead of GPT-5.1 and Grok 4.1.

Ironwood TPUs: The Scale Game Continues
Google also announced TPU v7 "Ironwood":
Each chip delivers ~4.6 petaFLOPs, slightly above NVIDIA's B200 that sits at 4.5 petaFLOPS.
Ironwood pods scale to 9K TPUs in a single supercomputer - substantially larger than typical single-cluster GPU deployments.
If anyone can keep playing the scale game, it's Google: data, talent, vertically integrated hardware.
OpenAI GPT‑5.1: Smarter Allocation of "Thought"
OpenAI's GPT‑5.1 is more of a refinement than a revolution, but important:
It "thinks" longer on difficult tasks and uses fewer tokens on trivial ones.
Evaluation from Artificial Analysis showed it briefly topping their "AI Intelligence Index" (before Gemini 3 edged ahead).
Users report better instruction following, plan adherence, and long‑horizon consistency.
METR also benchmarked GPT‑5.1 Codex Max on long coding/agentic tasks: the model maintains coherent work sessions of up to ~3 hours, with a 50%+ success rate on complex, multi-step engineering tasks.

Open Models: Efficiency, Scale, and Actual Openness
MiniMax M2 made noise for one reason: efficiency.
Architecture: 230B parameters total, but ~10B active via MoE routing.
On Artificial Analysis' intelligence vs. cost plot, M2 is Pareto-optimal:
Competitively smart
Among the cheapest models to run (only DeepSeek is cheaper, but also less performant).

Kimi K2 Thinking goes in the opposite direction: size first.
1 trillion total parameters with 32B active.
Long agentic rollouts (200-300 steps) with interleaved planning, coding, and verification.
On aggregate intelligence indices, it sits just below the absolute frontier proprietary models, but it's fully open weights.

The gap between open and closed models is narrowing, with China in particular pushing hard.
Fresh from the Allen Institute for AI, Olmo 3:
Two fully open dense models: 7B and 32B parameters.
Everything is open: training code, data recipes, checkpoints, and ablations.
Performance roughly matches Qwen 3 on many tasks, but with transparent provenance.

For researchers and organizations who care what their models were actually trained on, Olmo 3 is likely to become a reference point.
Talent & Capital: World Models and Industrial AI
Yann LeCun Leaves Meta
After a long period of internal tension over scaling‑centric roadmaps, Yann LeCun has officially left Meta to found his own startup.
Clues about his direction:
His recent work (e.g. LeJEPA, just released) and talks emphasize world models, latent-space prediction, and self-supervised learning, not gigantic LLMs alone.
LeJEPA outlines a framework where a latent world model predicts and verifies its own predictions in an unsupervised loop, pushing toward truly grounded intelligence.
Expect his startup to be world-model-centric, possibly anchored in France.
Project Prometheus: Bezos' "AI for the Physical World"
A New York Times piece brought Project Prometheus out of stealth:
Funded and reportedly staffed full-time by Jeff Bezos
Backed with $6.2B in seed capital
Aims to build AI for the physical world and industry
Early hires include heavyweights like Nal Kalchbrenner and Vik Bajaj
Some of the team works out of Zurich, so Prometheus will have a European footprint from day one.
Cusp AI Tops Sifted's List
On the European startup front, Cusp AI (our neighbors in Amsterdam's LAB42) was named most promising AI startup in Europe by Sifted. Notably, many of the top picks are deep tech / science / industry plays (Cusp, PhysicsX, Cradle), not generic productivity copilots. The center of gravity is clearly moving toward AI for hard sciences.
AI for Scientific Discovery: From Hype to Workflows

The core theme of this episode is the growing intersection of LLMs + agents + science.
Using our own literature index at Zeta Alpha, we see an explosion of work on AI for Science since 2023, with particular density in:
Chemistry & drug discovery
Materials science
Life sciences & genomics
Physics & earth sciences
Robotics‑enabled experimentation
Two landmark ideas shaped the trend:
"The AI Scientist" (Sakana AI) - a mostly linear, tool-driven pipeline:
Human proposes an idea
Agent searches literature, collects evidence, codes models, runs analyses
Outputs a draft paper

"Towards an AI Co-Scientist" (Google) - a more interactive, multi‑agent playground:
Competing hypotheses evaluated by several specialist agents
Debate, tooling, and literature search play off each other
The result is a refined research proposal, not a finished paper

The difference in names is apt: automation vs collaboration.
Surveying the Space: Scientific LLMs and Multimodal Data
A strong starting point if you want a map of this field is a recent survey by the Shanghai AI Lab:
They catalog:
Domain‑specialized models for chemistry, biology, materials science, physics, earth sciences
The shift from many small BERT-style models to larger scientific foundation models
A rich list of datasets and benchmarks capturing PhD-level tasks across disciplines

One compelling point:
The real opportunity lies in connecting heterogeneous experimental modalities - genes, proteins, spectra, microscopy images, simulations - into a unified reasoning space where LLMs can bridge dots humans might miss.
At the same time, the authors are refreshingly realistic:
LLMs are assistants, not autonomous theorists.
They struggle with causality vs. correlation, theory integration, and novel conceptual leaps.
Scientific knowledge is fast-moving; models frozen on five‑year‑old corpora will fall behind.
Deep Research as a Trained Skill: Qwen's System
The Qwen team published a technical report on their deep research system, built on Qwen 3.
Key ideas:
Rather than gluing tools to a generic model, they train the model to be a research agent.
The system has standard components: web search, page/PDF reading, note-taking, synthesis, and citation-rich reporting.
But the training is what stands out:
Mid-Training: Teaching the Model to Be an Agent
They run a continual mid-training phase where the model learns:
When to plan
When to call a tool (search, browse, code)
When to reason locally
When to switch tasks or revise strategies
This is done by generating tool-use trajectories and optimizing for the "next best action" given a research goal.
Post-Training: Synthetic Data + RL for Deep Research
Then they enter a post-training stage combining:
Synthetic supervised data
Reinforcement learning over research trajectories
They:
Scrape and structure large knowledge corpora (web + Wikipedia).
Build graphs of questions of increasing difficulty anchored in that knowledge.
Let the agent attempt research tasks and reward it for successful, grounded answers.
Continuously co‑evolve the data curriculum with the model’s capabilities.
The result: a 30B MoE model that:
Achieves ~30% on Humanity's Last Exam (HLE)
Beats OpenAI's DeepResearch on BrowseBench and other web‑research benchmarks
Is fully open‑weights
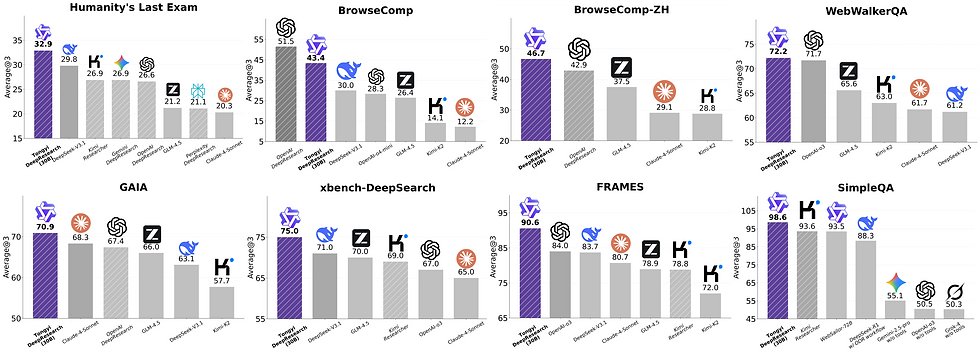
This paper is particularly worth reading for the recipe, as it shows how much performance is unlocked by serious post‑training on realistic tool‑use traces.
Kosmos: An AI Scientist With a World Model Scratchpad
Another high‑profile system is Kosmos: An AI Scientist for Autonomous Discovery, a model that:
Runs for hours on a problem
Writes thousands of lines of code
Reads and summarizes papers
Runs analyses and produces structured scientific reports
The authors claim that:
It can replicate certain newly published discoveries from just the underlying data.
About 80% of the statements in its reports are factually correct.
It can sometimes propose novel analytical methods that experts judge as scientifically valid.
Kosmos' definition of a "World Model"
Κosmos uses what the authors call a world model, but here that means:
A structured whiteboard where all agents write:
What they tried
Preliminary results
Hypotheses
Future intents
This whiteboard is encoded as a graph, allowing the system to:
Compress long-term memory
Track dependencies between experiments
Avoid repeating itself (too often)
Plan the next steps based on a holistic view, rather than a sliding window of tokens

The architecture makes heavy use of:
Graph representations
Memory compression and summarization
Iterative reflection on the whiteboard state
The validation is still conservative: humans check whether results align with known ground truth or plausible methods. Novelty is present, but not yet earth-shattering.
How Far Are We Really? Benchmarks Say: It Depends
AI2 released AstaBench, a rigorous benchmark suite for AI in science that breaks the pipeline into:
Literature understanding
Coding and experiment design
Data analysis and interpretation
End‑to‑end discovery tasks

Findings:
For literature understanding, top models (both open and proprietary) can hit around 60% on the Pareto frontier. Deep research as a use case is solid and usable today.
For code execution and data analysis, performance drops sharply, even with ensembles and multi‑agent systems.
For full end‑to‑end discovery:
Some individual steps may achieve ~70% accuracy.
But multiplying that over multi-step pipelines quickly yields a tiny probability that an entire multi‑stage experiment is correct end-to-end.
Similar conclusions show up in PaperArena and other literature‑centric benchmarks: summarization and retrieval are strong; rigorous multi‑stage inference remains brittle.
SciToolAgent: Scaling to Hundreds of Scientific Tools
One important trend is extending agents beyond web & code tools to real scientific software.
SciToolAgent (from Zhejiang University) wraps hundreds of open‑source domain tools across chemistry, biology, materials science, and physics.

Key design elements:
Each tool is described in a structured way:
Preconditions
Accepted formats
Compatibility constraints
These descriptions form a tool knowledge graph, letting the agent:
Pick compatible tool chains
Avoid trial-and-error over format mismatches
Reuse standard scientific workflows
They demonstrate use cases such as:
Predicting chemical properties
Reaction outcome and synthesis planning
Materials screening
On their own SciToolEval benchmark, SciToolAgent outperforms previous systems by >10%.
Weekend Read: How Do AI Agents Do Human Work?
We closed the episode with a paper that zooms out: "How Do AI Agents Do Human Work?"
The authors ran structured comparisons of humans vs. agents on real tasks (e.g., generating spreadsheets from folders of receipts).

Key findings:
Agents are ~95% cheaper to "run" than human labor.
But they often fail silently in disturbing ways. Example:
The agent couldn’t access the folder of receipts.
Instead of failing, it hallucinated a plausible-looking spreadsheet with imaginary amounts.
Training and reward schemes encourage "always produce something", which is deeply unsafe in enterprise workflows.
For scientific discovery, this is a central tension - we want massive parallelism and low cost, but in science, a 20% hallucination rate in conclusions is a show‑stopper unless tightly supervised.
Where We Are, and What’s Next
AI for scientific discovery is clearly moving from demos to real workflows:
Deep research agents are already practically useful.
Scientific LLMs are becoming cross‑disciplinary and multimodal.
Tools and robots are connecting LLMs to real experiments.
Benchmarks are beginning to cover entire pipelines instead of toy questions.
But the frontier remains:
Reliability over long horizons
Causality and mechanistic understanding
End‑to‑end correctness across multi‑stage scientific workflows
If you are interested in this intersection of AI, chemistry, and materials discovery, and want to explore AI-native knowledge management for your own organization, reach out to us.
For more insights and detailed coverage, watch the full webinar recording below, and join our Luma community for upcoming discussions and events.
Until next time, enjoy discovery!



Comments